
About the project
Objective
This project aims to create a real-time digital twin framework enhanced with physics-informed neural networks (PINNs) to guide the development of plant-based meat analogs. By integrating mechanistic modeling with AI, the framework will provide deeper insight into protein structuring and deliver accurate, efficient tools for predicting and optimizing texture.
Background
Food production is a major driver of climate change, biodiversity loss, and public health challenges. While the transition to plant-based diets offers clear sustainability benefits, consumer acceptance is limited by the difficulty of reproducing the texture of meat. Current development approaches rely on costly, time-consuming trial-and-error experimentation. This project pioneers a systematic, data- and physics-driven strategy to accelerate texture design, reduce development costs, and enable more sustainable, nutritious, and appealing plant-based foods.
About the Digital Futures Postdoc Fellow
Jingnan Zhang holds a PhD in Food and Nutrition Science. Her research integrates computational modeling and soft matter physics with food science, enabling a systems-oriented approach to connect digital technologies with sustainable and resilient innovations for the future of food.
Main supervisor
Francisco Javier Vilaplana Domingo, Professor, Department of Chemistry, KTH Royal Institute of Technology.
Co-supervisor
Anna Hanner, Associate professor, Department of Fibre and Polymer Technology, KTH Royal Institute of Technology.
About the project
Objective
There are abundant unlabeled and noisy data in research fields of modern biology and medical science. Naturally, estimating biological structures and networks from unlabeled and noisy data widens the scope of future AI-based research in biology, with directly actionable effects in medical science. The major technical challenge is development of robust AI and GenAI methods that can use information hidden in unlabeled and noisy data. A promising path to address the challenge is to include a-priori biological knowledge in developing models for signals and systems, and collecting data, and then regularize the learning of AI methods.
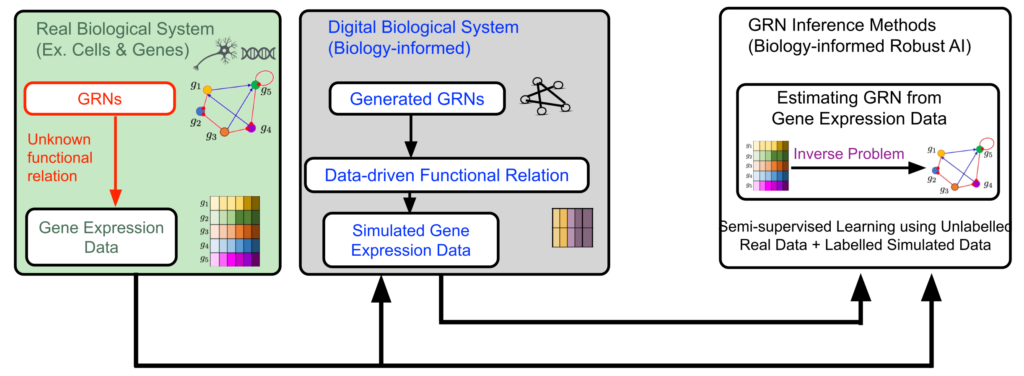
In pursuit of addressing the challenge, we focus on inference of gene regulatory networks (GRNs) from their noisy gene expression level data – a challenging inverse problem in biology. Understanding and knowing a GRN is a key for understanding biological mechanisms causing diseases such as cancer. While gene expression data is available in abundance, the data is unlabeled due to absence of knowing the true GRNs underneath. In addition, the expression data is noisy. So far, use of AI for robust estimation of large-size GRNs from unlabeled and noisy gene expression level data has been little exercised. Indeed, learning from unlabeled and noise data is challenging for AI methods. Here comes the motivation for the proposed project – Biology-informed Robust AI (BRAI). The objective of the BRAI project is to develop fundamental theory and tools for inferring complex biological structures and networks from unlabeled and noisy data using a-priori biological knowledge, focusing on the challenging inverse problem ‘GRN inference’.
Background
The human reference genome contains somewhere between 19,000 – 20,000 protein-coding genes. For human cells (ex. cancer cells), GRNs are large. In reality, the GRNs are not observed directly. They are observed through the gene expression data. Therefore, it is difficult to collect labeled data as pairwise GRN- and -expression data for training AI and machine learning (ML) in a standard supervised learning approach. On the other hand, there are gene expression data available in abundance as unlabeled data, without the true GRNs underneath.
The actual functional relationship between a GRN matrix and its expression data is governed by complex biophysics. For complex biological systems like cancer cells, the true functional relationship governing GRN-to- expression data is unknown, and difficult to model. In addition, the gene expression data is noisy, as the expression data contains not only information from the hidden GRN, but other known-and-unknown biological events.
Naturally, the GRN inference problem – estimating a large GRN from its noisy gene expression data without having labeled data and knowing their actual functional relationship – is a challenging inverse problem.
Cross-disciplinary collaboration
The project will combine methods and techniques from separate research fields – (a) biological knowledge about GRNs from bioinformatics and system biology, (b) graph theory and topological data analysis for network modeling from mathematics, and (c) robust machine learning (ML) and GenAI from AI / ML.
About the project
Objective
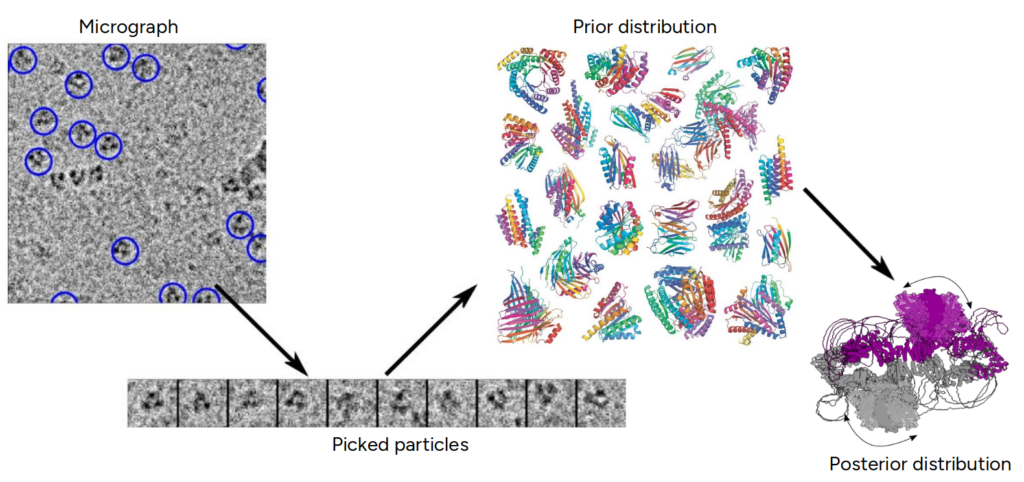
This project aims to advance the understanding of flexible protein dynamics by developing novel algorithms that integrate cryo-electron microscopy (cryo-EM) data with computational predictions using generative AI and statistical modeling. The goal is to overcome current limitations in protein structure prediction by accurately reconstructing continuous, atomic-resolution 3D structures and their dynamic variations. Ultimately, the project will provide transformative tools for the global life sciences community, enhancing insights into molecular functions critical for health, biotechnology, and medicine while strengthening Sweden’s leadership in AI4Science.
Background
Understanding the dynamic structures of flexible proteins is a major challenge in structural biology, as these molecules undergo continuous conformational changes essential for their biological functions. While cryo-electron microscopy (cryo-EM) has revolutionized the visualization of biomolecules at near-atomic resolution, capturing their full dynamic range remains difficult. Current computational methods, including AI-based predictions like AlphaFold, often fall short in modeling the continuous motions and heterogeneity of flexible proteins.
This project builds on advances in cryo-EM imaging, statistical modeling, and generative AI to develop new approaches that can more accurately reconstruct and analyze protein dynamics, addressing critical gaps in both experimental and computational techniques.
Cross-disciplinary collaboration
The project brings together experts from mathematics, machine learning, and structural biology to tackle complex challenges in biomolecular dynamics. Mathematicians contribute advanced statistical and inverse problem-solving techniques crucial for developing robust reconstruction algorithms. Machine learning specialists develop generative AI models to create data-driven priors that enhance the interpretation of cryo-EM data.
Finally, structural biologists provide essential expertise in cryo-EM methodologies, including sample preparation and image processing, ensuring high-quality experimental data, but more importantly provide critical domain expertise in order to design and evaluate the proposed methods.
About the project
Objective
This research aims to develop learning-to-optimize (L2O) methods to enhance real-time decision-making in modern energy grids. The focus is twofold: improving the efficiency of model predictive control under operational constraints, and accelerating the computation of Nash equilibria in competitive multi-agent scenarios.
By integrating machine learning with optimization, the project seeks to deliver solvers that are both fast and reliable, capable of generalizing across varying grid conditions. This work supports the broader goal of enabling more adaptive, efficient, and robust energy systems in the face of increasing complexity and renewable integration.
Background
The growing complexity of energy systems, driven by renewable energy, distributed assets, and diverse stakeholders, has created a pressing need for real-time, efficient decision-making tools. Traditional optimization methods often fall short under tight time constraints and non-convex, large-scale settings. However, many of these problems exhibit structural similarities across instances—such as similar dynamics or constraint patterns—which can be leveraged by learning-based methods. This repeated structure makes energy systems a natural fit for L2O approaches, which can learn from past problem instances to accelerate future optimization while maintaining feasibility and convergence.
About the Digital Futures Postdoc Fellow
Andrea Martin completed his PhD in Robotics, Control, and Intelligent Systems at EPFL, Switzerland, in 2025, with a thesis on optimal control and decision-making under uncertainty. His research interests include control theory, optimization, and machine learning. Prior to that, he earned master’s degrees in Automation Engineering from the University of Padua, Italy, and in Automatic Control and Robotics from the Polytechnic University of Catalonia, Spain, in 2020. He received his bachelor’s degree in Information Engineering from the University of Padua in 2017.
Main supervisor
Giuseppe Belgioioso, Division of Decision and Control Systems, KTH.
Co-supervisor
Mikael Johansson, Division of Decision and Control Systems, KTH.
About the project
Objective
This project will provide novel methodology to reconstruct the evolutionary history of cancer cells in their spatial context from widely used data. We will integrate single-cell and spatial transcriptomics data to reconstruct the evolutionary history of cancer cells and describe their spatial structure. These results will reveal how different cancer cell states arise and organize in space during tumor evolution, and how different states may be shaped by their interactions with the tumor microenvironment.
Background
Single-cell sequencing data has enabled highly detailed descriptions of intra-tumor heterogeneity in terms of the genotypes and phenotypes of cancer cells, as well as maps of the non-cancer cell types present within the tumor microenvironment. While standard single-cell sequencing techniques such as scRNA-seq provide detailed information on the cell states that make up a tumor, they do not capture the spatial distribution of the cells that it captures, which is lost in the process. In contrast, spatial transcriptomics technologies maintain the spatial structure of 2D tumor slices intact while still obtaining transcriptome-wide measurements of the cells therein. Integrating both data types may reveal novel therapeutic targets.
About the Digital Futures Postdoc Fellow
Pedro F. Ferreira holds a PhD in Computational Biology from ETH Zürich in Switzerland and a MSc in Electrical and Computer Engineering from IST in Portugal. He is interested in using single-cell sequencing data to reconstruct cell lineages and trajectories in order to identify key processes involved in tumor progression. To this end, Pedro has developed computational tools to characterize the populations of cells that constitute a tumor. These include learning the evolutionary history of cancer cells and identifying the gene expression patterns of malignant and normal cells. Pedro enjoys collaborating with biologists, bioinformaticians and machine learning experts in order to design powerful computational methods able to describe the heterogeneous populations of cells that constitute tumors.
Main supervisor
Jens Lagergren, KTH
Co-supervisor
Joakim Lundeberg, KTH.
About the project
Objective
The objective of the project is to identify and characterize clusters of patients and their dynamics over time such that the patients respond optimally to medical caregivers’ interventions and medications. In collaboration with Karolinska Institute and Region Stockholm, we will focus on dementia patients for personalized treatments and develop an advanced AI-based predictive analysis method to help medical caregivers for their decisions.
Background
It has been observed that patients suffering of a same disease can respond differently to the same medication. This can slow down medical treatments and even worsen the disease prognoses. How can we then make medical treatments personalized to improve the disease progression of patients over time?
Dementia patients have multiple follow-ups over time, generating longitudinal data. In a large patient pool, there can be several clusters, some representing patients who are more receptive and doing better with interventions and medications, and other clusters representing a more limited scope. Individual patients may also change clusters over time. Predictive analysis is required to make treatment decisions based on a patient’s personalized profile and the patient’s similarity across other patients over time. Modern sequence-based AI-methods are useful to make predictions on this type of data, and topological data analysis can give insights about characteristics and relations between patients by studying the shape of the data. These methods can help us find clusters of patients, characterize their disease progression and develop a decision care system for personalized treatments.
About the Digital Futures Postdoc Fellow
Belén García Pascual completed her PhD in biomathematics in October 2024 at the University of Bergen (Norway). She developed mathematical and computational models to explore questions in evolutionary and cell biology, with a focus on mitochondrial genes and evolutionary progression pathways of antimicrobial resistance. During the PhD, Belén did an industry internship at DNV in Oslo (Norway) researching how large language models can generate realistic synthetic data in healthcare. Before, she took her master in topology at the University of Bergen, and her bachelor in mathematics at Complutense University of Madrid (Spain).
Main supervisor
Martina Scolamiero
Co-supervisor
Saikat Chatterjee
About the project
Objective
This project aims to develop a deep learning-based methodology to enhance the ability to model complicated dynamics for sequential data. With a special focus on the recent progress of transformer-based models, which have shown great potential in modelling very long sequences, we are inspired to integrate them with other state-of-the-art techniques, such as learning dynamic structures and self-supervised learning. By exploring such directions, we expect our results to be applicable to the sequence modelling research and provide good insights for other fundamental deep learning research areas.
Background
Sequence modelling is the fundamental problem of other time series related tasks, including future forecasting. Since being proposed in 2018, transformers have become the de facto choice for most sequence modelling tasks due to their superior performance over traditional RNN-based approaches. However, it appears that transformers usually need a significant amount of training data to achieve their full potential, making them an expensive and impractical option for many real-world scenarios. Thus, it becomes increasingly imperative to develop methods to effectively train transformers with limited labelled data, which is quite common for sequence modelling.
About the Digital Futures Postdoc Fellow
Hao Hu is a postdoc researcher at KTH RPL working with Hossein Azizpour. Before joining KTH, he worked as a research scientist in FX Palo Alto Laboratory (FXPAL), California, United States. Hao got his PhD in Computer Science from the University of Central Florida (UCF) in 2019. His research interests include various topics in machine learning and computer vision, with a special focus on temporal modelling and deep learning.
Main supervisor
Hossein Azizpour, Assistant Professor, Robotics, Perception and Learning, KTH.
Co-supervisor
Arne Elofsson, Professor in Bioinformatics, Stockholm University.